개인 프로젝트 목적으로 네이버 지도에서 특정 매장의 정보를 수집하고 싶었다.
2일정도 이 작업에 매진했는데, 결과적으로는 난관에 봉착했고 현재는 실패 상태로 멈췄다.
그 이전까지의 고군분투 과정과 해결하지 못한 포인트를 소개한다.
문제 1. 크롤링? 해도 될까?
첫번째 문제는 크롤링을 해도 되는지 윤리적/법적/정책적 측면의 고민이 들었다.
사이트의 크롤링 허용 여부는 robots.txt를 확인하면 된다. 네이버 지도 사이트의 robots.txt 내용은 아래와 같았다.
User-agent: *
Disallow: /
Allow: /$
Allow: /p/$
위 내용은 누가 크롤링을 하던지, 정확히 지도의 루트 주소(map.naver.com/와 map.naver.com/p/)를 제외하고는 크롤링을 일체 금지한다는 내용이다. 주소 하위의 추가적인 path나 query를 허용하지 않는다. 즉, 네이버 지도에서 검색어를 넣었을 때 나오는 결과 화면의 크롤링을 금지한다는 내용이다.
robots.txt 파일은 법적 효력이 없다고 한다. 정보가 대중에게 공개된 이상, 크롤링 자체를 법적으로 처벌할 근거는 없는 것으로 이해했다(내가 법적 지식은 부족하기에 확신하지 못하겠다). 하지만, 거대 플랫폼들 사이의 경쟁에서는 크롤링이 문제가 된 경우가 있는 것으로 보인다. 여기어때와 야놀자의 사례가 그렇다. 또한, 네이버의 사용 정책에서도 robots.txt의 허용 범위에 위배되는 사용 패턴이 감지되면 서비스 사용에 불이익을 감수해야 한다는 내용이 있었다. 고로 상업적 이용은 물론, 개인 프로젝트더라도 찝찝한 구석은 남아있다. 법적인 책임을 물어야 하지는 않더라도, ip 밴 정도는 충분히 당할 수 있어보였다.
그러나, 구글링을 조금만 해보더라도 네이버 지도 크롤링 사례나 크롤링 도구들이 많이 나온다. 네이버씩이나 되는 대기업이 개인 프로젝트에 법적 책임을 묻는 일은 잘 일어나지 않기 때문으로 보인다. 그래서 양심 상, 그리고 ip밴을 피하기 위한 의도 상 아래의 결정을 내렸다.
- 크롤링을 막는 이유는 지적 재산권 보호의 목적도 있지만, ddos 공격으로부터의 서비스 보호 목적도 있다. 내 HTTP 요청이 네이버 서버에 ddos처럼 다뤄지지 않도록, GET 요청은 손수 애드혹(adhoc)하게 진행한다.
- 내 크롬 브라우저에 랜더링된 정보를 내가 가공하기 좋은 형태로 정제하는 작업은, 사람이 손으로도 할 수 있는 작업이고 네이버 서버와도 무관하므로 자동화한다.
이렇게 결정하여 만들기로 한 도구는 사실 크롤링이란 용어를 쓰기에도, 다소 멀어졌다. 고로, 아래부터는 크롤링 대신 자동화 도구라는 표현을 사용하겠다.
문제 2. 네이버 지도의 주소 파헤치기: 좌표로 검색하기
앞서 말했듯이, 내 자동화 도구는 특정 주소의 화면에 랜더링된 정보들을 내가 다루기 좋은 형태로 가공하는 일을 한다. 아래의 기능을 원한다.
입력: 매장 검색의 기준이 될 위도(lat), 경도(lng) 좌표
출력: 해당 좌표를 기준으로 검색한 네이버 지도 화면의 정보들을 가공한 형태
이걸 구현하기 위해서는 네이버 지도 주소의 규칙을 역공학(reverse engineering)해야한다. 네이버 지도 검색 결과 화면을 구할 때 필요한 입력은 "검색 위치"와 "검색어" 두가지다. HTTP 응답(response)들로 미루어보아, 네이버 지도 서버는 이 두 입력을 바탕으로 매장들에게 우선도 점수를 책정하여, 점수가 높은 순으로 사용자에게 매장을 노출 시키는 것으로 보였다. 검색어를 입력했을 때 리다이렉션되는 주소 결과들을 보며, 네이버 지도 주소의 규칙을 파악했다. 아래의 주소로 접근하면 원하는 검색결과 화면을 획득할 수 있었다.
from pyproj import Transformer
# lat, lng, keyword는 주어졌다고 가정
encoded_keyword = urllib.parse.quote(keyword)
transformer = Transformer.from_crs("EPSG:4326", "EPSG:3857")
x, y = transformer.transform(lat, lng)
URL = f"https://map.naver.com/p/search/{encoded_keyword}?c={x},{y},15.22,0,0,0,dh"
lat, lng에 적절한 위도 경도 값과 keyword에 검색어가 채워지면, URL을 통해 검색 결과 화면으로 이동할 수 있다. 검색어는 한국어를 이용할 경우 URL에 들어가기 적합하도록 인코딩하고, 지도 상 검색 기준 좌표는 위도/경도 좌표와는 다른 좌표를 사용하기 때문에 적절히 변환했다. '15.22'라는 숫자는 내가 임의로 정했다. 지도의 축척을 의미하고, 숫자가 커질수록 더 좁은 면적을 구체적으로 보여주는데 15.22 라는 값이 내가 원하는 매장 정보를 빠짐없이 수집하기 적절해보였기 때문이다. 그 뒤의 숫자들은 보여지는 지도의 유형을 변경하는 값들인데 나에게는 별 도움이 되지 않는 옵션이었다.
문제 3. 화면에서 필요한 정보 수집하기
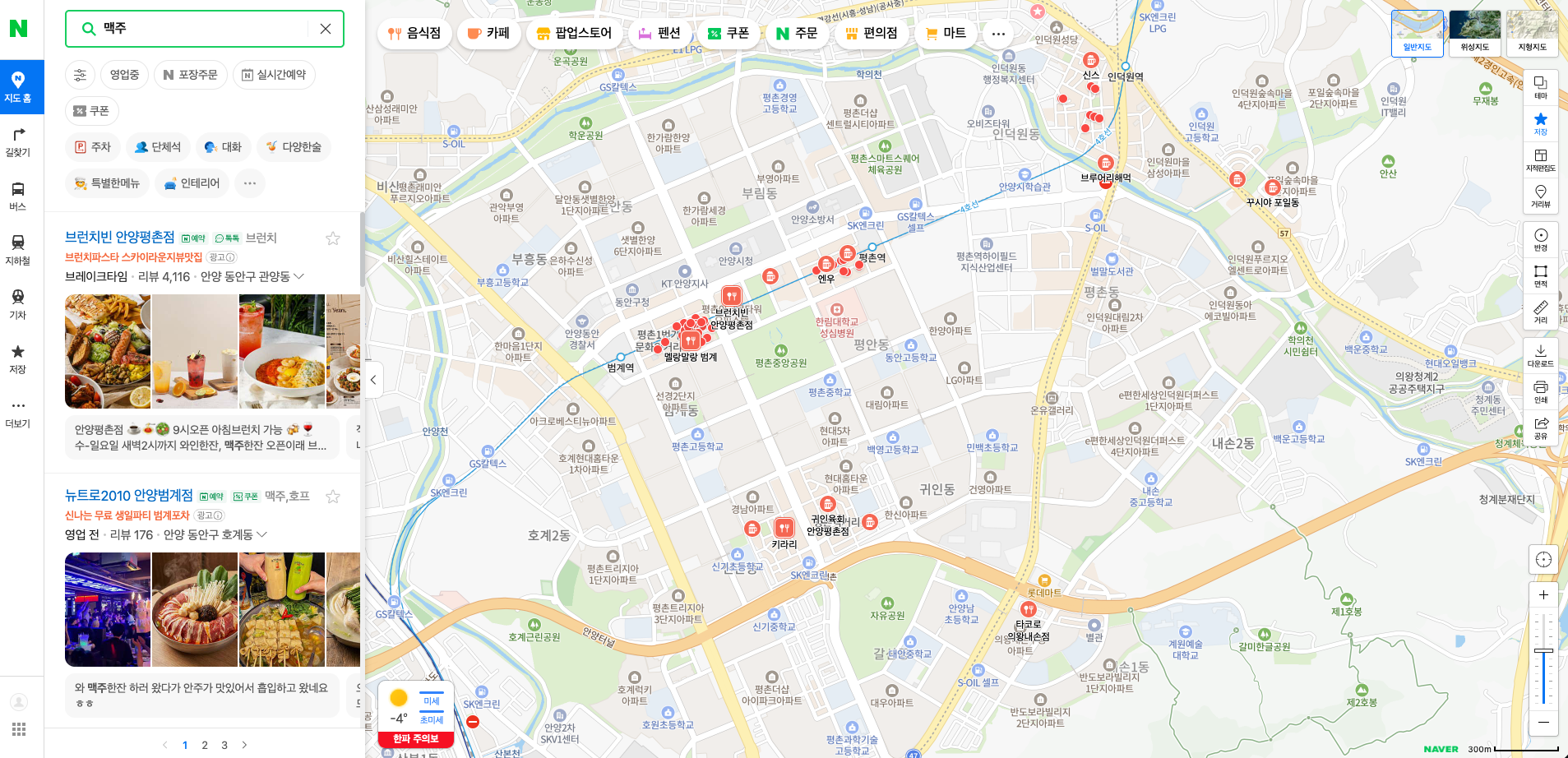
이제 검색결과 화면 속 정보를 수집해야 하는데 아직 적절한 방법을 찾지 못했다. 두 가지 방법으로 접근했다. 첫번째는 화면에 그려진 html 요소들을 바탕으로 정보를 얻는 방법이다. 두번째는 이 화면을 구성할 때 사용된 HTTP response를 직접 활용하는 방법이다.
방법 1. HTML 요소들로부터 정보 얻기
흔히 크롤링을 할 때, 일반적으로 이 방법을 이용한다. 가게의 이름은 이 블로그의 코드를 참고하여 쉽게 작성할 수 있었다. 작성한 코드의 내용을 쉽게 말하면, 가게 리스트의 스크롤을 최하단까지 내려 모든 정보를 로딩한 후(네이버 지도는 한 번에 모든 정보를 랜더링하지 않고, 스크롤 상태에 따라 필요한 만큼 정보를 로딩한다), 화면에 있는 모든 가게이름 요소에 xpath를 통해 접근하여 텍스트를 추출하는 것이었다. 그렇게 가게 이름 리스트는 아주 쉽게 획득했다.
그러나, 나는 가게의 지도상 좌표도 필요했다. 지도의 가게 정보 마커는 CSS의 transform을 통해 제 위치에 그려진다. 그러므로, 현재 보여지고 있는 지도의 좌표, 지도의 배율, 지도 상에서 마커의 위치를 계산하여 좌표를 구하고 해당 마커와 대응되는 가게 이름을 매칭하면 된다. 말로 하면 간단하지만 코드를 작성하려 하니 생각보다 복잡하고, 더 다양하고 구체적인 정보를 획득할 수 있을 것으로 보이는 방법2로 고개를 돌렸다.
방법2. HTTP response를 직접 활용하기
크롬 개발자 도구의 네트워크 탭을 역공학(reverse engineering)하면, 역시나 네이버 지도 클라이언트가 화면을 그리기 위해 필요한 정보들을 파악할 수 있다. 이 정보들이야말로, 네이버 지도가 화면을 그리기 위해 필요한 모든 정보와 정확한 값이 완전히 가공되지 않은 날 것의 상태이기에 내가 다루기 아주 좋은 정보다.
다양한 위치 기준을 바탕으로 애드혹하게 정보를 수집하기로 했기 때문에, 내가 지도 위치를 옮겨 다니며 정보 수집 상태를 주시하기 편하도록 구글 크롬 확장(extension)의 형태로 개발에 착수했다. 보안 문제로 아주 간편하게 HTTP response body를 훔쳐볼 수 있는 chrome API는 없다. 그래서, 다소 hacky한 접근으로 아래의 방식들을 생각해봤다.
- Chrome Devtool API를 이용하여, 직접 개발자 도구의 네트워크 탭에 접근하는 방식.
- window.fetch 함수를 response body를 출력하도록 내가 작성한 새로운 fetch 함수로 대체하는 방식. 이른바 몽키 패칭(Monkey Patching)
- Chrome background에서 chrome.debugger API를 붙여 사용하는 방식. Debugger가 "Network.responseReceived" 이벤트를 감지했을 때, payload를 꺼내보면 송신된 HTTP response를 얻을 수 있음.
첫번째 방법은 난이도가 높고, 두번째 방법은 우아하지 않다는 생각이 들어 세번째 방법을 선택했다. 그 결과, 네이버 서버로부터 날아오는 모든 HTTP response를 콘솔에 출력하는 것까지 성공했다. 그러나, 또 다른 문제에 봉착했다.
네이버 지도는 한 페이지에 80개의 가게를 보여주는데, 사용자가 리스트를 스크롤 할 때 마다 필요에 맞게 20개씩 fetch해오는 방식을 사용하고 있었다. 페이지 최초 랜더링 시, 첫 20개의 가게는 HTTP response로 전달되는 것을 확인했다. 문제는 나머지 60개의 가게 정보가 어느 시점에 로딩되는지 역공학에 실패한 것이었다. 지도 검색 시 서버로부터 내려오는 모든 HTTP response를 확인했으나 가게 정보를 찾을 수 없다. 아마도, 나머지 정보들은 protobuf 혹은 다른 방식으로 인코딩되어 전송되는 것이 아닐까 추측되는데, 그렇다면 내가 원하는 정보가 어디에 있고 어떻게 인코딩된 값인지를 찾아 그것을 디코딩하는 로직을 추가하는 것이 또 난이도 있는 작업이었다.
아무튼, 현재까지 네이버 지도로부터 내가 원하는 정보를 수집하는 작업은 속 시원한 방법을 찾지 못했다. 조만간, 깔끔한 해답을 찾아서 새로운 글을 작성할 수 있기를 바란다.
'개발이야기' 카테고리의 다른 글
| Spring Boot 프로젝트 시작 시 생기는 모든 파일의 역할 (0) | 2026.04.18 |
|---|---|
| TCP의 혼잡제어(congestion control) (0) | 2026.02.26 |
| 개발 생산성을 높이는 MCP의 개념과 Cursor AI 설정법 (0) | 2025.07.16 |
| OCaml에 대해 실전 속성 압축으로 익혀보기 (0) | 2025.06.22 |
| VSCode 환경에서 make로 빌드되는 c파일 gdb로 디버깅하기 (0) | 2025.06.16 |