이 글은 DATABASE SYSTEMS:The Complete Book(2nd Edition, Hector Garcia-Molina, Jeffrey D. Ullman, Jennifer Widom)의 Chapter4: High-Level Database Model의 4.1~4.6절을 요약/재구성한 글입니다.
현실의 정보들을 데이터베이스에 담으려고 하면, 어떤 정보를 어느 릴레이션에 담고, 서로 어떻게 참조 관계를 구성할지 고민이 될 수 있다. 데이터베이스 디자인을 관계형 모델(Relational model)을 이용해서 바로 접근할 수도 있지만, 그것을 추상화하는 한단계 높은 레벨의 모델을 사용할 것이다.
4.1 The Entity/Relationship Model
E/R Model은 데이터 구조를 시각적으로 표현해준다. 세가지로 구성된다.
- 엔티티 셋(Entity Sets)
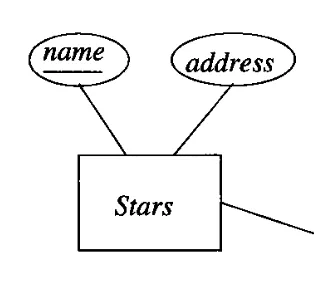
- Relational model에서의 릴레이션과 비슷한 역할이다. 엔티티가 하나의 추상적인 오브젝트라면, 그 집합이 엔티티 셋이다. 직사각형으로 표현한다.
- 속성(Attributes)
- Relational model에서의 속성과 비슷한 역할이다. 타원으로 표현한다.
- 관계성(Relationships)
- 엔티티 셋들간의 관계이다. Movies와 Stars의 두 엔티티 셋간에는 “Stars-in”이라는 커넥션이 있다. 세 개 이상의 엔티티들 끼리도 관계를 가질 수 있다. 마름모로 표현한다.
이 셋을 조합하면 이런식으로 그려진다.

관계성(Relationships)
관계형 모델과는 다르게, E/R 모델에는 인스턴스라는 개념은 없다. 하지만 관계성이 뭔지 이해하기 위해 관계성 셋(relationship set)이라는 개념이 있다. 어떤 관계성 R이 엔티티셋 E1과 E2간의 관계라면, 각각의 셋에서 튜플을 하나씩 골라 (e1, e2)의 새로운 튜플로 만들 수 있다. 아래는 Movies와 Stars 엔티티셋에서 연결된(connected) 관계성 셋 이다.

두 엔티티셋 E, F에 대해서, E의 엔티티 하나가 최대 1개의 F의 엔티티와 연결된다고 하자. 다르게 말하면, F의 입장에서는 여러개의 E와 연결될 수 있다. 이 관계성을 다대일(Many-to-one) 관계성이라 부른다.
E와 F의 엔티티가 서로 최대의 한개씩만 연결된다면 일대일(one-to-one)관계성이라고 부른다. 그 외에 E와 F의 엔티티가 아무렇게나 연결되어 있다면 다대다(many-to-many) 관계성이라고 부른다.
E/R 다이어그림을 그릴때, 화살표의 머리가 향한 곳은 관계성 셋에서 최대 한개만 있을 수 있다는 뜻이다. 아래의 그림들 처럼 표현할 수 있다.
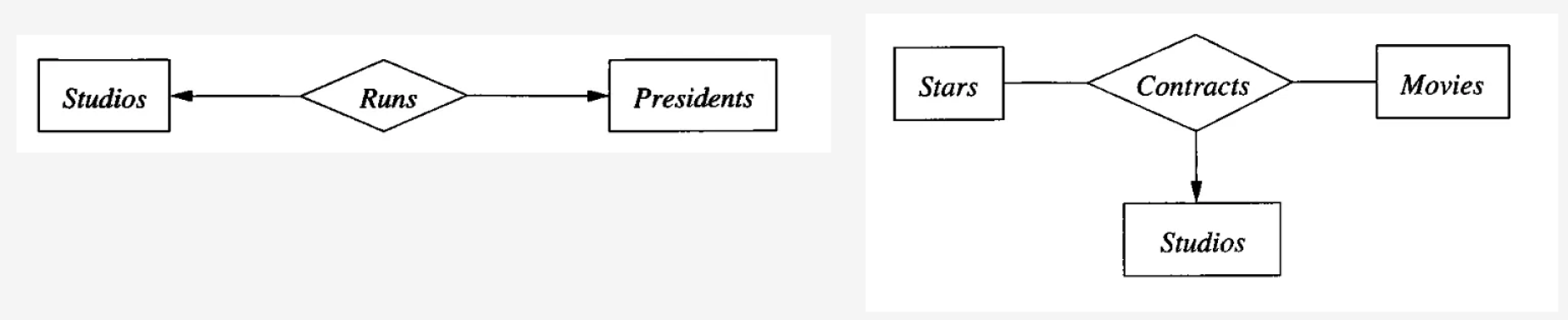
한 관계성안에 동일한 엔티티셋이 두번 등장할 수도 있다. 그 경우에는 화살표 위에 반드시 역할(role)을 적어주어야한다.

엔티티셋 뿐만 아니라 관계성도 속성을 가질 수 있다. 아래가 그 예시이다.

우리는 지금까지 관계성 위에 3개 이상의 선을 그어 엔티티셋과 연결했다. 그런데 종종, UML, ODL과 같이 다른 다이어그램으로 표현하고자 할때는 3개 이상의 선은 문제가 된다. 그래서 아래와 같은 시도도 가능하다.
- 관계성이 속성을 갖고 있을 경우, 그 속성을 옮길 새로운 엔티티 셋을 만들어 옮겨준다.
- 관계성과 엔티티 셋 간의 연결이 여러개 일 경우, 관계성을 대신할 새로운 엔티티 셋인, 연결 엔티티셋(connecting entity set)을 만들어, 기존 엔티티셋과 새로운 관계성을 맺는다.

엔티티셋 안에서, 몇몇 엔티티에게만 특별한 속성이나 관계성을 주고 싶을 수도 있다. 그럴때는 서브클래스(subclass)를 이용한다. “A is a B”에서 따온 “isa”라는 관계성으로 또 아래처럼 표현할 수 있다. Movies는 Cartoons일수도 있고, Murder-mysteries일수도 있다. 둘 다 아닐수도 있고, 둘 다 일수도 있다. 그리고, 화살표는 그리지 않았지만, isa는 일대일 관계성과 같음을 생각해 볼 수 있다.

(4.2절은 스킵합니다.)
4.3 Constraints in the E/R Model
엔티티셋 또한, 릴레이션 처럼 키를 갖는다. 키는 밑줄을 그어 표현한다.
또, 참조무결성(Referential Integrity)을 표현할 수도 있다. 화살표는 해당 엔티티가 최대 1개 있다는 뜻이지만, 끝이 둥그런 아래의 화살표는 반대편 엔티티가 존재하면 항상 해당 엔티티도 존재해야함을 의미한다. Owns에서 studios는 모든 movies에 대해서 항상 존재한다. Runs에서도 studios는 모든 presidents에 대해서 항상 존재한다. 하지만, studios에 presidents는 1개 있거나 없을 수도 있다.

마지막으로, 개수를 표현할 수도 있다. 아래 그림에서는, Movies 엔티티 하나가 10개가 넘는 stars 엔티티와 연결될 수 없다.

4.4 Weak Entity Sets
어느 엔티티셋의 키가 다른 엔티티 셋의 속성들로 이루어지면, 그것을 약한 엔티티 셋(Weak entity set)이라고 부른다. 언제 이 개념이 필요할까?
첫째로, 두 엔티티가 계층적인 관계에 있을때를 의미한다. 앞서 말한 서브클래스와는 다르다. 현실의 종(species)과 속(genus)같은 분류체계가 예시가 될 수 있다. 혹은 studio에 crew1, crew2, … 가 속한다고 생각해보자. Crew의 숫자는 키가 될 수 없고, studio의 속성을 빌려와야 할 것이다.
둘째로, 관계성이 엔티티 셋으로 표현된 connecting entity set의 경우이다. 앞선 예시에서, movies와 stars 사이의 contracts에 salary라는 속성이 있었는데, salary가 contracts의 키가 될 수 있을리는 없다.
약한 엔티티셋은 스스로 키를 가지지 않으므로, 그들에게 키를 제공하는 supporting entity set과 다대일의 supporting relationship을 맺어야한다. 다이어그램 상으로는, supporting entity set을 향한 둥근 화살표가 적어도 하나는 있어야 할 것이다.
다이어그램 상으로는 약한 엔티티셋과 supporting relationship은 테두리를 두 줄로 그어 표현한다. 아래의 그림은 앞서 설명한 약한 엔티티셋의 개념을 모두 설명한다.

4.5 From E/R Diagrams to Relational Designs
이제 ER 다이어그램을 관계형 모델로 변환할것이다. 아래의 두 규칙을 따른다.
- 엔티티셋을 같은 속성을 가진 릴레이션으로 바꾼다.
- 관계성(relationship)을 릴레이션으로 바꾼다. 속성은 relationship set 에 있는 속성과 연결된 엔티티셋의 키들이다.

위의 다이어그램은 아래와 같은 관계형 모델로 변환할 수 있다.
Stars(name, address)
Movies(title, year, length, genre, studioName)
Studios(name, address)
StarsIn(starName, movieTitle, movieYear)
Owns가 없고, Movies에 studioName이라는 속성이 들어간 이유는 아래의 예외 케이스에 포함되기 때문이다. 예외는 아래의 3가지 경우가 존재한다.
- 다대일 관계에서는 관계성으로부터 변환된 릴레이션을 “다” 쪽의 엔티티와 합칠 수 있다.
- 약한 엔티티셋은 릴레이션으로 바꾸지 않는다.
- “Isa” 관계성은 4.6절에서 다루는 방법을 이용한다.
1번 예외. “다”쪽인 엔티티셋과 관계성셋의 릴레이션을 합칠 수 있다. 위의 예시에서 Owns는 다대일 관계이다. 그래서, Owns 릴레이션은 "다"쪽인 Movies로 합쳐져, studioName이라는 속성으로 남아있다. 혹여나 Owns 관계가 자체로 속성을 갖고 있었다면, 그 역시 Movies 쪽으로 합쳐 줄 수 있다. 혹여, “다”쪽 엔티티가 "일"쪽 엔티티셋과 연결되어있지 않은 경우도 있는데(studio가 없는 movie가 있다거나), 이 경우에는 “다”쪽 속성들 외의 값은 모두 NULL인 튜플로써 표현하면 된다.
2번 예외. 별개의 릴레이션으로 만들되, supporting entity의 key를 속성으로 포함한다. 또, supporting relationship은 릴레이션으로 만들지 않는다. 아래의 예시에서, Crews에 studioName이 있음과 Unit-of 릴레이션은 없음에 주목하라. 사실 이 예외는 1번 예외의 연장선으로 볼 수도 있다.

Studios(name, addr)
Crews(number, studioName, crewChief)
3번 예외는 바로 아래의 4.6절로 분리해서 다룬다.
4.6 Convertin Subclass Structures to Relations

위의 movie 다이어그램을 3가지 방법으로 변환할 수 있다.
첫번째는 ER-스타일 변환방법이다.
Movies(title, year, length, genre)
MurderMysteries(title, year, weapon)
Cartoons(title, year)
Voices(title, year, starname)
눈여겨 볼점은, MurderMysteries와 Cartoons에 length와 genre 속성이 없다는 것이다. MurderMysteries나 Cartoons에 있는 튜플은, 모두 대응되는 튜플이 Movies에도 있을것이다.
또, Cartoons가 Voices의 부분집합이라는 점도 볼만하다. 이 설계에서는, Cartoons에 존재하지 않지만, voices에만 존재하는 숨은 튜플이 존재할 수 있다. 이 경우, 삭제한 voices가 해당 cartoons의 정보를 담은 마지막 voices 였다면, cartoons 라는 정보를 유실하게되는 삭제 이상이 발생한다.
두번째는 객체지향적인 접근(object-oriented approach)이다.
Movies(title, year, length, genre)
MoviesMM(title, year, length, genre,weapon)
MoviesC(title, year, length, genre)
MoviesCMM(title, year, length, genre, weapon)
Voices(title, year, starname)
Voices가 MoviesC와 VoicesCMM 모두와 연결되어있을 수 있다는 점이 특이하다.
세번째는 Null을 이용한 접근이다. 모든 속성을 Movies 하나에 때려넣고 없으면 Null을 값으로 갖는다.
Movies(title, year, length, genre, weapon)
Voices(title, year, starName)
어떤 접근이 가장 좋은가? 당연하게도 접근마다 장단점이 존재한다.
- 쿼리 연산량
정보를 쿼리할 때, 릴레이션이 하나뿐인 Null 접근은 매우 간단하다. 반면, 나머지 두 접근은 쿼리의 종류에 따라 복잡해질 수 있다. 단순히, “150분보다 긴 영화”를 찾고 싶다면, ER-스타일에서는 Movies만 확인하면 그만이지만, OO-스타일은 무려 4개의 릴레이션을 뒤져야 한다. 반면, “150분보다 긴 카툰에 쓰인 무기”라고 하면 OO-스타일에서는 MoviesCMM만 확인하면 될 것을, ER-스타일에서는 3개의 릴레이션을 다 뒤져야 한다.
- 릴레이션의 수
N개의 서브클래스가 있다고하자. Null 접근은 릴레이션이 무조건 하나다. ER-스타일은 (n+1)개다. OO-접근은 무려 2^n개다.
- 저장공간과 데이터의 중복
OO-접근은 엔티티당 튜플이 하나이므로, 공간과 데이터 중복도 측면에서 유리하다.
Null 접근은 엔티티당 튜플이 하나이기는 하나, 튜플 하나의 속성이 많아서, 공간의 낭비가 발생한다. 서브클래스가 많아질수록 이 공간 낭비는 심해질 것이다.
ER-접근은 엔티티 하나에 튜플이 여러개이므로, 불리해보이지만, 중복되는 정보는 키뿐이다. Null 접근과 비교하면 상황에 따라 다르다.
'개인 공부' 카테고리의 다른 글
| [데이터베이스 개론] 5. 데이터베이스의 언어 SQL(The Database Language SQL) (1) | 2025.06.16 |
|---|---|
| [데이터베이스 개론] 4. 대수적/논리적 쿼리 언어(Algebraic and Logical Query Language) (0) | 2025.04.22 |
| [데이터베이스 개론] 2. 관계형 데이터베이스 설계(Design Theory for Relational Databases) (0) | 2025.04.22 |
| [데이터베이스 개론] 1. 관계형 데이터 모델(Relational Data Model) (0) | 2025.04.21 |
| [이산구조] 명제(Proposition) (0) | 2025.03.02 |